
近日,国家纳米科学中心施兴华团队联合清华大学高华健团队开发了一种基于强化学习的增强采样方法—Adaptive CVgen,并成功将其应用于研究蛋白质折叠和富勒烯(C60)合成问题。该成果以Adaptive CVgen: Leveraging Reinforcement Learning for Advanced Sampling in Protein Folding and Chemical Reactions为题,发表在《美国国家科学院院刊》(PNAS)上。
解析微观体系的动态演化过程是基础研究中的一个重要难题,涵盖了多个前沿领域,如蛋白质折叠、药物研发、材料设计等。在实验手段上,目前尚缺乏有效的方法来精确解析微观体系的动态过程。以冷冻电镜为例,它能够解析蛋白质的晶体结构,但仅能捕捉到稳定的静态信息,而无法揭示其瞬态或者动态演化过程。相比之下,理论计算方法在探索微观体系的动态行为方面展现出优势。目前主流的研究工具可分为三大类:基于深度学习的结构预测工具、分子动力学模拟、以增强采样方法为主的长时间模拟方法。
以AlphaFold为代表的深度学习工具在预测蛋白质结构方面取得了巨大的成功,也因此获得了今年的诺贝尔化学奖,但它无法预测其折叠的动力学过程。传统的分子动力学方法因其模拟的时间尺度有限,通常仅适用于平衡态附近的体系。增强采样方法可进行长时间尺度模拟,因而前景广阔。但现有的成功应用大多仅局限于少数简单体系,其普适性尚未得到充分验证,亟需开发具有广泛适用性的增强采样方法以应对日益复杂的科学挑战。
Adaptive CVgen 属于自适应采样方法的范畴,这类方法的一个显著特点是在模拟过程中不改变体系的自由能面形貌,因此能够同时获取体系的热力学和动力学信息。Adaptive CVgen 方法具有两个创新之处:一是引入了高维反应坐标,可覆盖体系演化过程中可能出现的各种状态;二是利用强化学习整合高维反应坐标以预测体系演化的方向。在蛋白质折叠研究中,该方法展现出卓越的普适性,无需调整任何参数即可成功模拟包含多种二级结构的蛋白质折叠动态过程。值得注意的是,研究中所涉及的体系对于现有技术手段而言均具有极大的挑战性。这一成果推动了复杂体系长时间模拟的研究进程。
Adaptive CVgen 具有广泛的应用潜力,可推广至更为复杂的体系,如生物催化、基因表达与调控、药物设计与开发、化学合成、催化反应、工程材料等诸多学科领域。这一方法的推广有望进一步推动复杂体系动力学研究的发展,为相关领域提供全新的思路与工具。
国家纳米科学中心博士生沈文辉为论文第一作者,国家纳米科学中心施兴华研究员、清华大学高华健院士为论文通讯作者。该工作得到了国家重点研发计划、国家自然科学基金和中国科学院先导专项的资助。
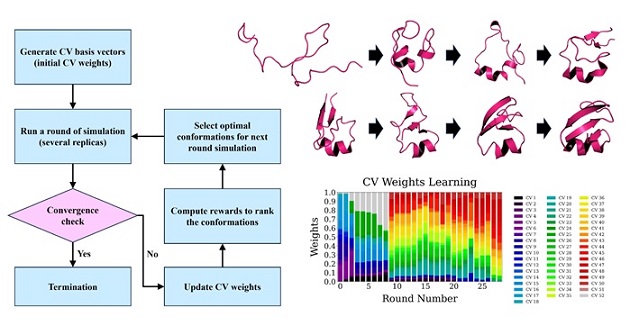
图1. Adaptive CVgen方法流程图
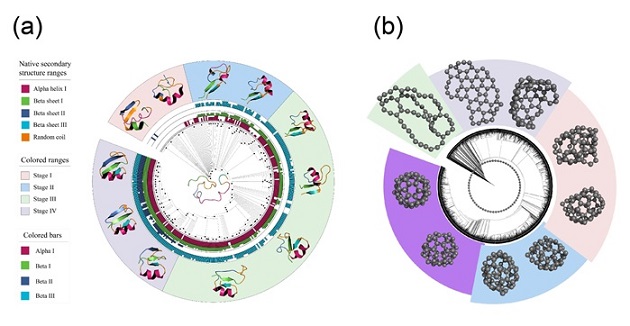
图2. 由Adaptive CVgen 采样得到的构象演化过程。(a)展示了蛋白质(PDBid:2hba)从无序到有序、从不稳定到稳定的演化路径,揭示了蛋白折叠中的关键动力学机制;(b)展示了从二维到三维、从无序到有序的复杂转变,揭示了C60合成中的关键演化路径

